The Definitive Guide to the Gemini 3 Release and Its Benchmarks: Is Google's New AI the GPT-5.1 Killer?

If you're a developer, researcher, or AI enthusiast trying to see the next frontier of AI, here's an in-depth look at what matters most about the Gemini 3 release.
🧠 State-of-the-Art Reasoning: Beyond the Benchmarks
The core of Gemini 3's power lies in its state-of-the-art reasoning capabilities. Google claims the model can solve extremely complex, multi-step problems with a level of depth and nuance previously unseen.
The proof is in the numbers: Gemini 3 Pro outperforms GPT-5.1 and Claude Sonnet 4.5 on every major benchmark according to Google's internal testing, achieving a groundbreaking score on the notoriously difficult Humanity's Last Exam.
Deep Think Mode: The Enhanced Reasoning Feature
For the most demanding analytical tasks, Google is introducing Gemini 3 Deep Think mode. This enhanced reasoning feature is configured for researchers and Ultra subscribers, offering a level of depth analysis that pushes model performance even further on high-difficulty benchmarks. It represents Google's commitment to providing a unique analytical companion for scientific and complex content queries.
💻 Agentic Coding for Developers Gets a Major Upgrade
For the engineering community, the Gemini 3 release signals a revolution in developer workflows. The model excels at agentic coding for developers, meaning it can autonomously plan, use tools, and execute complex, multi-step software tasks over long periods—acting like a true junior developer.
Vibe Coding: From Idea to Application
The promise of "vibe coding"—turning a high-level, spontaneous language idea into a fully functional application—is now fully realized. Developers can describe what they want in natural language, and Gemini 3 will generate complete, working applications with interactive UIs, proper code structure, and even embedded AI assistants.
Google Antigravity Platform
The model's power is housed within the new Google Antigravity platform, an agentic development environment where AI agents work across editors, terminals, and browsers to autonomously manage and execute code. This is where developers can start experimenting with Gemini 3's best-in-class agentic capabilities.
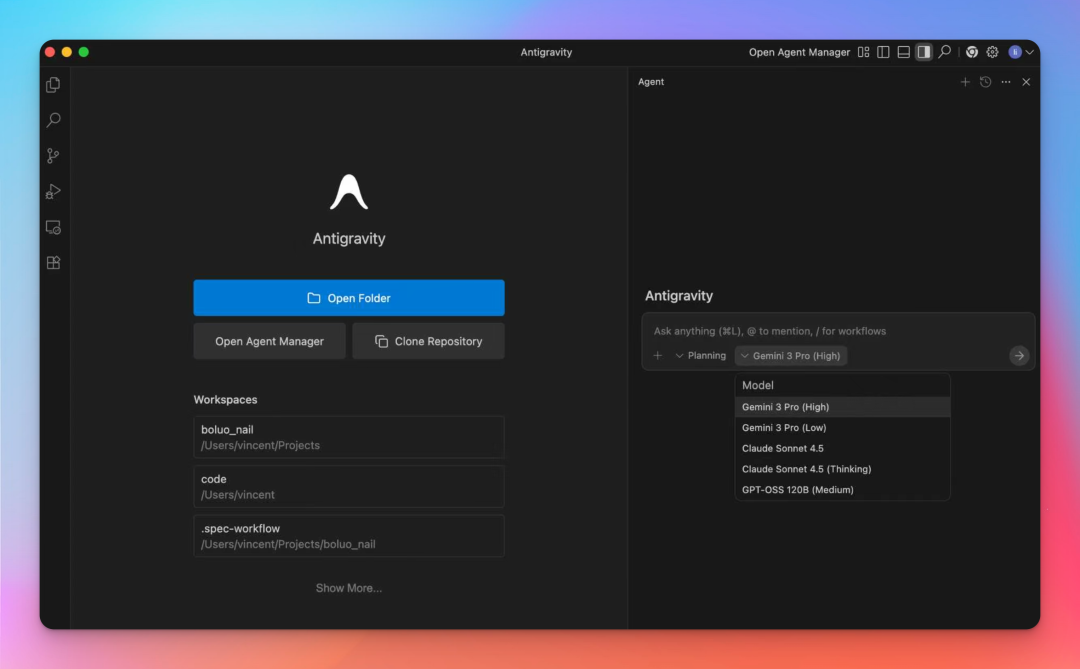
The Antigravity IDE provides a comprehensive development environment with integrated AI agents, workspace management, and support for multiple AI models including Gemini 3 Pro, Claude Sonnet 4.5, and GPT-OSS 120B.
Key Features of Antigravity:
- Free access to Gemini 3 Pro and Claude Sonnet 4.5
- Autonomous code generation and execution
- Multi-tool integration (editors, terminals, browsers)
- Long-horizon task planning and execution
- Workspace management with recent projects
- Agent manager for creating and managing AI agents
- Support for multiple AI models (Gemini 3 Pro High/Low, Claude Sonnet 4.5, GPT-OSS 120B)
🖼️ Unparalleled Multimodal and Multilingual Understanding
Gemini 3 was built as a pure multimodal model, seamlessly processing all forms of data. It is now widely established as the best model in the world for multimodal understanding.
This capability means:
Video Analysis: The model understands movement, timing, and linguistic context within video, allowing for applications like analyzing sports performance or turning video lectures into comprehensive notes.
Dynamic Interfaces: When you prompt it for a complex plan (like a holiday travel guide), Gemini 3 dynamically generates an interactive, visual user interface—not just a block of text. This is a game-changer for user experience.
Multilingual Excellence: It delivers exceptional performance in multilingual reasoning, effortlessly translating complex concepts, like a written formula, across multiple languages.
🔑 How to Get Access to Gemini 3 Pro for Free Today
The great news for users and developers is the immediate and broad accessibility of the new model.
| User Section | Access Point | Model Version | Availability |
|---|---|---|---|
| General Users | Gemini App (free tier) | Gemini 3 (with limits) | Rolling out globally now |
| Search Users | AI Mode in Google Search | Gemini 3 Pro (for complex queries) | Rolling out now |
| Developers/Students | Google AI Studio | Gemini 3 Pro (preview/free tier) | Available today via API |
| Subscribers | Gemini App (Pro/Ultra) | Gemini 3 Pro (higher limits) & Deep Think | Ultra access rolling out soon |
To find out how to access Gemini 3 Pro for free, just navigate to the Gemini App or Google AI Studio and start prompting!
📊 Gemini 3 Benchmarks vs GPT-5.1: Comprehensive Comparison
While independent analysis is ongoing, Google's own data suggests a significant lead, especially in complex reasoning and agentic tasks. Here's a detailed breakdown of how Gemini 3 Pro performs across 20 major benchmarks:
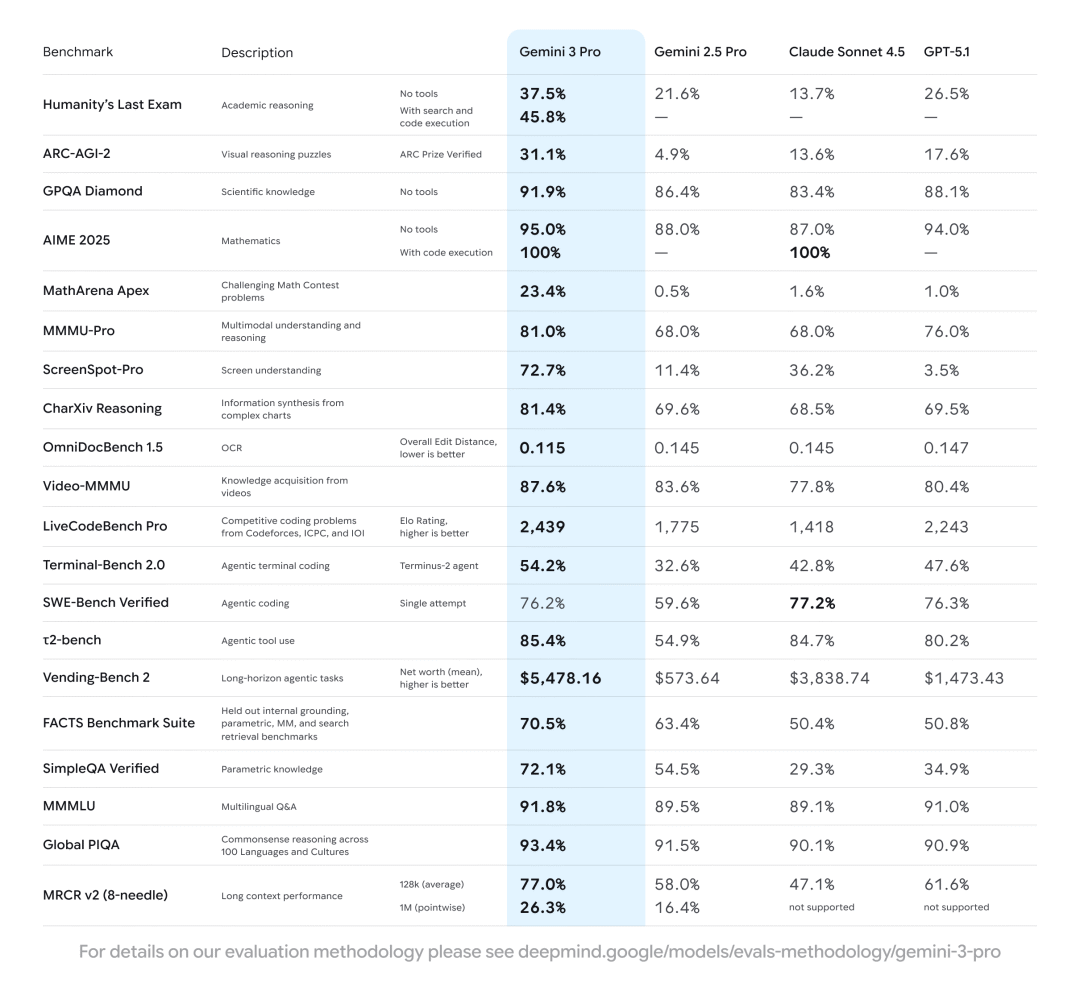
Comprehensive benchmark comparison showing Gemini 3 Pro's performance across 20 major benchmarks against Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5.1.
Academic and Reasoning Benchmarks
Humanity's Last Exam (Academic reasoning, No tools)
- Gemini 3 Pro: 37.5% 🏆
- Gemini 2.5 Pro: 21.6%
- Claude Sonnet 4.5: 13.7%
- GPT-5.1: 26.5%
Gemini 3 Pro leads significantly, demonstrating PhD-level reasoning capabilities.
ARC-AGI-2 (Visual reasoning puzzles, ARC Prize Verified)
- Gemini 3 Pro: 31.1% 🏆
- Gemini 2.5 Pro: 4.9%
- Claude Sonnet 4.5: 13.6%
- GPT-5.1: 17.6%
Gemini 3 Pro shows a strong lead in visual reasoning, nearly doubling GPT-5.1's performance.
GPQA Diamond (Scientific knowledge, No tools)
- Gemini 3 Pro: 91.9% 🏆
- Gemini 2.5 Pro: 86.4%
- Claude Sonnet 4.5: 83.4%
- GPT-5.1: 88.1%
Gemini 3 Pro is the top performer in scientific knowledge benchmarks.
Mathematics Benchmarks
AIME 2025 (Mathematics)
- No tools:
- Gemini 3 Pro: 95.0% 🏆
- Gemini 2.5 Pro: 88.0%
- Claude Sonnet 4.5: 87.0%
- GPT-5.1: 94.0%
- With code execution:
- Gemini 3 Pro: 100% 🏆
- Claude Sonnet 4.5: 100% 🏆
- GPT-5.1: Not provided
Gemini 3 Pro and Claude Sonnet 4.5 achieve perfect scores with code execution.
MathArena Apex (Challenging Math Contest problems)
- Gemini 3 Pro: 23.4% 🏆
- Gemini 2.5 Pro: 0.5%
- Claude Sonnet 4.5: 1.6%
- GPT-5.1: 1.0%
Gemini 3 Pro significantly outperforms others, achieving over 23x the performance of GPT-5.1.
Multimodal Understanding Benchmarks
MMMU-Pro (Multimodal understanding and reasoning)
- Gemini 3 Pro: 81.0% 🏆
- Gemini 2.5 Pro: 68.0%
- Claude Sonnet 4.5: 68.0%
- GPT-5.1: 80.8%
Gemini 3 Pro is the top performer, closely followed by GPT-5.1.
ScreenSpot-Pro (Screen understanding)
- Gemini 3 Pro: 72.7% 🏆
- Gemini 2.5 Pro: 11.4%
- Claude Sonnet 4.5: 36.2%
- GPT-5.1: 3.5%
Gemini 3 Pro demonstrates a substantial lead, achieving over 20x the performance of GPT-5.1.
CharXiv Reasoning (Information synthesis from complex charts)
- Gemini 3 Pro: 81.4% 🏆
- Gemini 2.5 Pro: 69.6%
- Claude Sonnet 4.5: 68.5%
- GPT-5.1: 69.5%
Gemini 3 Pro leads in chart understanding and reasoning.
OmniDocBench 1.5 (OCR - Overall Edit Distance, lower is better)
- Gemini 3 Pro: 0.115 🏆
- Gemini 2.5 Pro: 0.145
- Claude Sonnet 4.5: 0.145
- GPT-5.1: 0.147
Gemini 3 Pro has the lowest (best) edit distance, indicating superior OCR accuracy.
Video-MMMU (Knowledge acquisition from videos)
- Gemini 3 Pro: 87.6% 🏆
- Gemini 2.5 Pro: 83.6%
- Claude Sonnet 4.5: 77.8%
- GPT-5.1: 80.4%
Gemini 3 Pro leads in video understanding and analysis.
Coding and Agentic Benchmarks
LiveCodeBench Pro (Competitive coding problems from Codeforces, ICPC, and IOI - Elo Rating, higher is better)
- Gemini 3 Pro: 2,439 🏆
- Gemini 2.5 Pro: 1,775
- Claude Sonnet 4.5: 1,418
- GPT-5.1: 2,243
Gemini 3 Pro achieves the highest Elo rating in competitive programming.
Terminal-Bench 2.0 (Agentic terminal coding - Terminus-2 agent)
- Gemini 3 Pro: 54.2% 🏆
- Gemini 2.5 Pro: 32.6%
- Claude Sonnet 4.5: 42.8%
- GPT-5.1: 47.6%
Gemini 3 Pro is the top performer in agentic terminal tasks.
SWE-Bench Verified (Agentic coding - Single attempt)
- Claude Sonnet 4.5: 77.2% 🏆
- Gemini 3 Pro: 76.2%
- GPT-5.1: 76.3%
- Gemini 2.5 Pro: 59.6%
Claude Sonnet 4.5 performs best, closely followed by Gemini 3 Pro and GPT-5.1 in a tight race.
t2-bench (Agentic tool use)
- Gemini 3 Pro: 85.4% 🏆
- Gemini 2.5 Pro: 54.9%
- Claude Sonnet 4.5: 84.7%
- GPT-5.1: 80.2%
Gemini 3 Pro leads, with Claude Sonnet 4.5 very close behind.
Vending-Bench 2 (Long-horizon agentic tasks - Net worth mean, higher is better)
- Gemini 3 Pro: $5,478.16 🏆
- Gemini 2.5 Pro: $573.64
- Claude Sonnet 4.5: $3,838.74
- GPT-5.1: $1,473.43
Gemini 3 Pro achieves the highest net worth, indicating superior performance in long-horizon planning and execution.
Knowledge and Grounding Benchmarks
FACTS Benchmark Suite (Held out internal grounding, parametric, MM, and search retrieval benchmarks)
- Gemini 3 Pro: 70.5% 🏆
- Gemini 2.5 Pro: 63.4%
- Claude Sonnet 4.5: 50.4%
- GPT-5.1: 50.8%
Gemini 3 Pro is the top performer in factual knowledge and grounding.
SimpleQA Verified (Parametric knowledge)
- Gemini 3 Pro: 72.1% 🏆
- Gemini 2.5 Pro: 54.5%
- Claude Sonnet 4.5: 29.3%
- GPT-5.1: 34.9%
Gemini 3 Pro shows a significant lead in parametric knowledge tasks.
Multilingual Benchmarks
MMMLU (Multilingual Q&A)
- Gemini 3 Pro: 91.8% 🏆
- Gemini 2.5 Pro: 89.5%
- Claude Sonnet 4.5: 89.1%
- GPT-5.1: 91.0%
Gemini 3 Pro is the highest, with GPT-5.1 close behind.
Global PIQA (Commonsense reasoning across 100 Languages and Cultures)
- Gemini 3 Pro: 93.4% 🏆
- Gemini 2.5 Pro: 91.5%
- Claude Sonnet 4.5: 90.1%
- GPT-5.1: 90.9%
Gemini 3 Pro is the top performer in multilingual commonsense reasoning.
Long Context Benchmarks
MRCR v2 (8-needle) (Long context performance)
- 128k (average):
- Gemini 3 Pro: 77.0% 🏆
- Gemini 2.5 Pro: 58.0%
- Claude Sonnet 4.5: 47.1%
- GPT-5.1: 61.6%
- 1M (pointwise):
- Gemini 3 Pro: 26.3% 🏆
- Gemini 2.5 Pro: 16.4%
- Claude Sonnet 4.5: Not supported
- GPT-5.1: Not supported
Gemini 3 Pro leads in long context understanding, and is the only model with a score for the 1M context evaluation.
🎯 Key Takeaways for Your Use Case
| Capability | Gemini 3 Score | Key Takeaway for Your Site |
|---|---|---|
| Academic Reasoning (Humanity's Last Exam) | 37.5% | Target users seeking PhD-level reasoning and academic help. |
| Agentic Coding (Terminal-Bench 2.0) | 54.2% | Target developers searching for agentic coding capabilities. |
| Multimodal Understanding (MMMU-Pro) | 81.0% | Target users with specific video and image analysis needs. |
| Long-Horizon Planning (Vending-Bench 2) | $5,478.16 | Ideal for complex, multi-step agentic tasks. |
| Competitive Coding (LiveCodeBench Pro) | 2,439 Elo | Best choice for competitive programming and algorithm challenges. |
🚀 Real-World Applications and Capabilities
Based on extensive testing, Gemini 3 Pro demonstrates remarkable capabilities in practical applications:
Website Replication
Gemini 3 can replicate entire website homepages with a single prompt. Testers have successfully recreated interfaces for platforms like Bilibili, X (Twitter), TikTok, and Xiaohongshu with impressive accuracy.
Interactive Application Generation
The model can generate fully functional applications from natural language descriptions. One of the most impressive demonstrations is Gemini 3's ability to perfectly replicate design mockups and add sophisticated interactive animations and effects—all from a simple prompt.
Watch Gemini 3 perfectly replicate a design mockup with interactive animations and effects—demonstrating its exceptional understanding of design intent and ability to generate production-ready code.
Examples of what Gemini 3 can create include:
- Weather card applications with dynamic UI
- Interactive games (like a playable Plants vs. Zombies clone)
- 3D animation demonstrations (e.g., DNA double helix replication)
- Complete operating system interfaces with embedded AI assistants
- Design mockup replication with full interactivity and animations
Architecture Diagram Recreation
Users can upload architecture diagrams, and Gemini 3 will recreate the page with editable text, making it easier to modify and iterate on designs.
Code Quality Improvements
Compared to Gemini 2.5 Pro, Gemini 3 shows significant improvements in:
- Code generation quality and structure
- Agent capabilities for autonomous task execution
- Better instruction following (e.g., correctly omitting quotation marks when requested)
- Enhanced code organization and architecture
📈 Performance Summary
In summary, Gemini 3 Pro consistently leads across most benchmarks, often by a significant margin, particularly in areas like:
- ✅ Visual reasoning (ARC-AGI-2: 31.1% vs GPT-5.1's 17.6%)
- ✅ Challenging math problems (MathArena Apex: 23.4% vs GPT-5.1's 1.0%)
- ✅ Screen understanding (ScreenSpot-Pro: 72.7% vs GPT-5.1's 3.5%)
- ✅ OCR accuracy (OmniDocBench: 0.115 vs GPT-5.1's 0.147)
- ✅ Video understanding (Video-MMMU: 87.6% vs GPT-5.1's 80.4%)
- ✅ Competitive coding (LiveCodeBench Pro: 2,439 Elo vs GPT-5.1's 2,243)
- ✅ Long-horizon agentic tasks (Vending-Bench 2: $5,478.16 vs GPT-5.1's $1,473.43)
Claude Sonnet 4.5 shows strong performance in SWE-Bench Verified (77.2%) and matches Gemini 3 Pro on AIME 2025 with code execution (both achieving 100%).
GPT-5.1 is competitive in some academic and multimodal benchmarks but generally trails Gemini 3 Pro across most evaluations.
Gemini 2.5 Pro typically performs lower than Gemini 3 Pro and the other leading models, highlighting the significant leap forward in Gemini 3.
🎓 LMArena Rankings
According to independent testing, Gemini 3 Pro has achieved a score of 1501 points on LMArena, placing it at the top of the leaderboard—further validating its position as the current strongest multimodal model globally.
🔮 The Future of AI Development
The Gemini 3 release is not just an update; it's a leap forward that truly establishes a new high-water mark for the AI industry. With its combination of:
- PhD-level reasoning capabilities
- Unmatched multimodal understanding
- Revolutionary agentic coding features
- Free and accessible deployment across multiple platforms
Gemini 3 represents a significant milestone in the journey toward more capable, accessible AI systems.
💭 Conclusion
What complex, multi-step task are you most excited to try first using Gemini 3 Deep Think mode or the Google Antigravity platform? The possibilities are endless, from autonomous code generation to complex research analysis, from interactive application creation to advanced video understanding.
The era of "vibe coding" and truly autonomous AI agents is here. Whether you're a developer looking to accelerate your workflow, a researcher seeking advanced analytical capabilities, or simply an AI enthusiast curious about the cutting edge, Gemini 3 Pro offers unprecedented opportunities to explore what's possible with artificial intelligence.
Get started today: Visit Google AI Studio or download the Gemini App to begin experimenting with Gemini 3 Pro's capabilities.
Last updated: January 2025. Benchmark data based on Google's official release and independent testing. Performance may vary based on specific use cases and prompts.